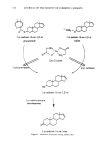
ANTIPERSPIRANT RESULTS 17 5 Standard Deviation 800 700 600 + 500 + 400 + 300 + 200 + A A 100 A A A A A A A A A A A A A A A A A AA AAAA AAA A B A BAA AC A AAAAAABBAAA BA A ABAAB ABA A A AAAAABBB B BAB A A A B DAABA AA A A ADC AA A AA A AABA AA A AAA A A A A A A A AA A A A A A A Mean Sweat Rate Figure 5. Test subject baseline axillary sweat rates: Plot of standard deviation versus mean by subject. original metric (Figure 7) but not in the log metric (Figure 8). Correlation analysis confirmed that the log transform reduces the dependence of variability on sweat level to negligible levels. This analysis strongly confirms Wooding's thesis that sweat rate data should be log transformed before performing any parametric statistical analyses (such as the t-test) that assume the data have a normal (or Gaussian) distribution. This will be further confirmed in analyses of efficacy studies later on. Arithmetic handling of raw sweat rates or their ratios followed by parametric statistical analysis must be considered as suspect, even with large numbers of data, due to the skewness of their distributions and dependence of their variability on their average sweat rate. A fortunate mathematical consequence of the log transformation is the benefit of being easily applied to the sweat reduction calculation, since log(T) - log(C) = log(T/C), and percent sweat reduction of T versus C is a simple function of the log sweat rate ratio: PCTRED = 100 * (! - !0**log(T/C)) where logarithms are to the base 10 and the symbol ** denotes exponentiation.

176 JOURNAL OF THE SOCIETY OF COSMETIC CHEMISTS Log Standard Deviation 0.35 0.30 + 0,25 0.20 0.15 + A A A A A A A A A A A A A A A A A A A A A A A A A A AA A A A A AA AA A A A A A A B A B A A A A A A A A A B A A AA A AA A A A A AA AA A A AA A AA AB A A A AA A A A A AA AA A BA A A AAA A A A AA A A AA A B A A A A AA A AA A B A 0.1.0 + A A A A A A A A A 0.05 Log Mean Sveat Rate Figure 6. Test subject baseline axillary log(sweat rates): Plot of standard deviation versus mean by subject. THE POSTRT MODEL FOR ANALYSIS OF POST-TREATMENT DATA Further consideration of the experimental design leads to an extension of the SSEM model. The assignment of treatments to experimental units is made in such a way that each treatment is applied to the left axilla for half the subjects and to the right axilla for the other half. Subjects are randomly placed in one of two groups: those having treat- ment "T" on the left and "C" on the right (Group 1), and those with the opposite assignment (Group 2). Subjects may be considered as larger experimental units assigned to one of the two levels of a factor called "groups." Axillae may be considered as smaller experimental units assigned a value of each of the two factors, "sides" and "treatments." In statistical parlance this is a "split plot" design, i.e., there is more than one size of experimental units, with units of each size assigned to levels of different sets of factors. Since subjects are randomly assigned to groups, any difference in group means should be subject only to random chance, with an expected value of zero. However, the "groups" factor is aliased with the treatment-sides interaction. If the interaction exists, it leads to the conclusion that the comparative efficacy of two treatments depends upon which side of the body the test treatment is applied. It is important to note that this interaction effect must be tested against main plot error, which is the variation due to subject differences in mean sweat rate.
Purchased for the exclusive use of nofirst nolast (unknown) From: SCC Media Library & Resource Center (library.scconline.org)