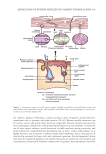
300 JOURNAL OF COSMETIC SCIENCE the images with high and low scores in each group were paired exhaustedly in all possible combinations, such as AX, AY, AZ, BX, BY, BZ, etc., as shown in Table II. In addition, images in each pair were switched from left to right to form a reversed-order sequence for the panel to evaluate for a second time to further minimize potential bias. As the result, the 36 subjects in 6 groups generated a total of 108 image pairs and the corresponding comparison events. A panel of 77 female Chinese volunteers (aged 21–64 years old with median of 38 years old), who were seasoned skincare product users, evaluated the skin conditions of the image pairs one at a time and answered a simple question: which image (left or right of the pair) is better in terms of ideal complexion? Overall, the 77 panelists each judged 108 pairs of images to produce a total of 8,316 binomial responses. An average was taken between the normal and the reversed-order sequences, and therefore 54 unique paired-comparison events were finally obtained. Panel responses to the paired-comparison events were analyzed to determine the difference, in terms of panel preference toward ideal complexion, between each of the 54 unique pairs of images. The analysis was carried out by calculating the odds of picking Figure 1. Sample skin ROI and the visual effect of some detected skin visual attributes: (A) color-corrected front-view image of a subject under Standard 2 lighting modality with a large skin ROI outlined within a yellow borderline (B) skin ROI cropped out of the facial image (C) skin ROI with shine pixels highlighted (D) ROI with wrinkles, fine lines, and pores highlighted (E) ROI with red spots highlighted and (F) ROI with dark spots highlighted.

301 Characterizing and Modeling Complexion the “good complexion image” in each pair and then taking the logit function (log of odds, designated as Logit(A)) to transform the panel responses (in binary format) into a normally distributed dataset such that the probabilities of the panelists’ preferences were mapped to scales (ranging from negative infinity to positive infinity) and normally distributed (36,37). MODELING Statistical analysis and mathematical modeling were conducted using JMP-12, a commercially available statistical software package (SAS Institute, Cary, NC, USA). The standard least squares method was used to establish correlations between the panel-perceived differences, Logit(A), and the combined effects of skin visual attributes measured by image analysis. Since the panel results indicated the differences in image pairs, it was essential to match the properties of the measured skin attributes to those of panel responses. It was achieved by calculating the differences of the measured skin visual attributes for each image pair. Equation 1 shows the definition of such differences, where P represents any one of the objectively measured skin visual attributes A, B, or C represents the high-translucency-score group and X, Y, or Z represents the low-score group. Equation P P P e g., ITA° ITA° A B,orC X,Y,orZ A X 1. .,∆ =-∆ITA ° =-()The Bradley–Terry model, a probability model that can predict the outcome of a paired comparison (38–40), was employed to convert the Logit(A) results to a ranking order in terms of panel preference toward ideal complexion for the 36 study subjects. Image pairs of intra- and inter-group comparison necessary for the Bradley–Terry model but not covered in the original study design were created, and their corresponding panel preferences were simulated using the Logit model. JMP multiple linear regression was used again to correlate the preference ranks and the skin attributes to obtain a final model that can calculate ICS for each of the 36 study subjects. Figure 2 shows the flow chart of the modeling process. Table II Sample of Subject Pairing – Group 6 Pair ID Pair Translucency Score Age ITA° Value A, B, or C X, Y, or Z A, B, or C X, Y, or Z A, B, or C X, Y, or Z 61-La AX 5 7 56 56 21.6 22.5 62-L BX 4 7 54 56 29.8 22.5 63-L CX 5 7 54 56 27.7 22.5 64-L AY 5 6 56 47 21.6 24.4 65-L BY 4 6 54 47 29.8 24.4 66-L CY 5 6 54 47 27.7 24.4 67-L AZ 5 7 56 52 21.6 23.5 68-L BZ 4 7 56 52 29.8 23.5 69-L CZ 5 7 54 52 27.7 23.5 a Notation for pair ID: 6 =group number 1 =pair number L =high-score image placed on the left.
Purchased for the exclusive use of nofirst nolast (unknown) From: SCC Media Library & Resource Center (library.scconline.org)